AI inference cost / Commercial comparison
API vs Self-Hosted Inference: Which Costs Less?
Short answer: API inference usually wins for uncertain or low-volume workloads; self-hosted inference can win when volume, utilization, latency, or control needs justify GPU operations.
- Compare total monthly serving cost per successful request, not token price against GPU hourly rate.
- Verify current provider pricing directly before buying or migrating.
Next action
Compare serving modes
Use this page when the question is whether API simplicity still beats GPU control after utilization, latency, and operations are included.
Run the calculator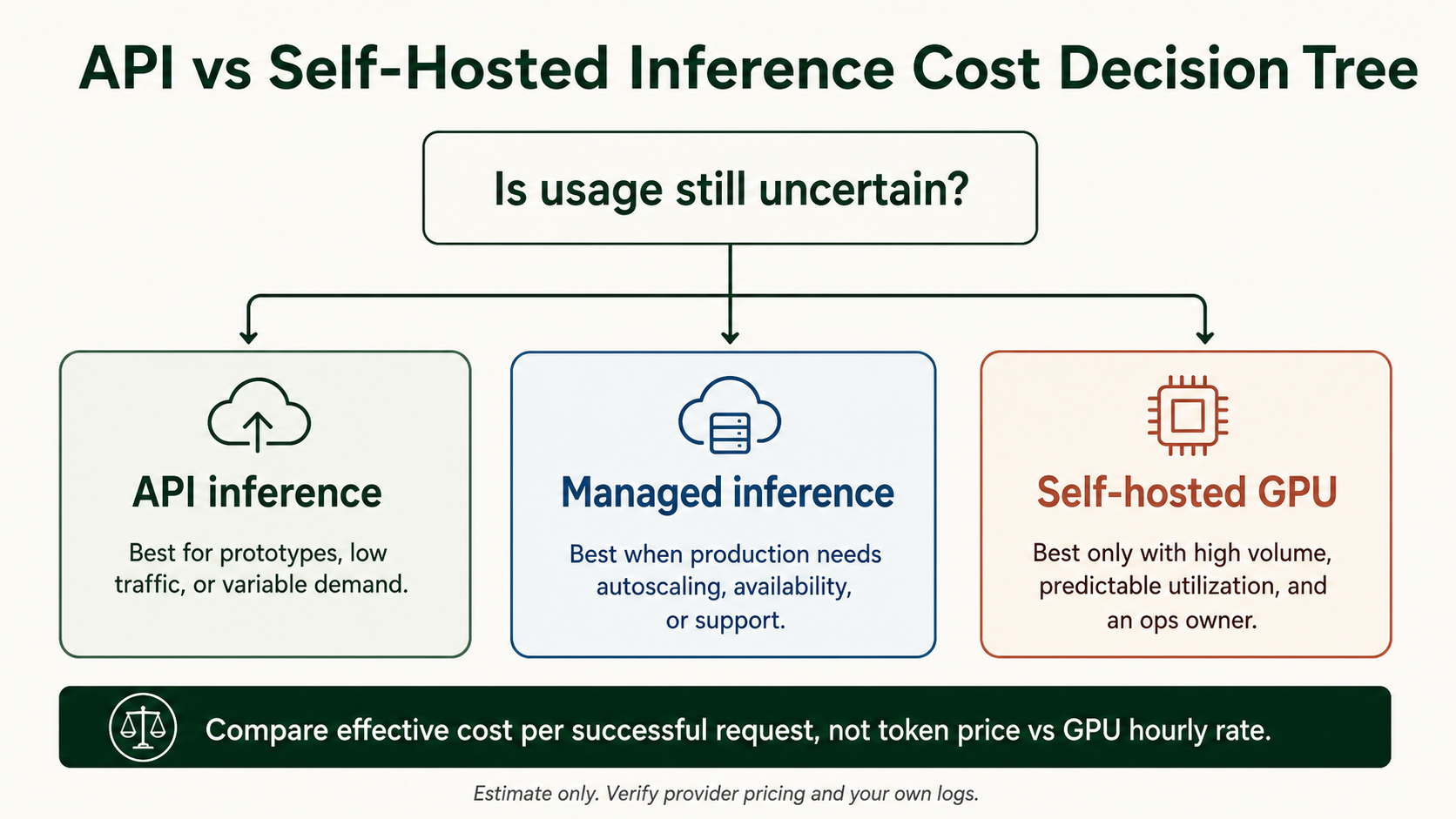
Decision tree
API vs self-hosted inference cost decision tree
Use this tree as a first filter before comparing exact provider rates. It is directional and should be replaced with your own logs, quotes, and current provider pricing before buying capacity.
Is usage still uncertain?
If request volume, latency, output size, or retry behavior is still changing, avoid carrying fixed GPU capacity too early.
Prototype, low traffic, or variable demand
API inference usually fits while you are exploring demand, model fit, and product behavior with low operations tolerance.
Production needs autoscaling or support
Managed inference can win when batching, autoscaling, deployment support, and shared incident ownership offset the platform premium.
High volume, predictable utilization, and an ops owner
Self-hosted GPU only becomes plausible when utilization is high, control matters, and the team can operate serving, monitoring, upgrades, and incidents.
Open the AI inference cost calculator when you have request volume, token usage, GPU quote, or managed serving assumptions.
Right fit
- You are deciding whether to keep using an AI model API or run inference on your own GPU capacity.
- Traffic volume, latency, or margin pressure is making the current setup questionable.
- The team needs a provider-neutral way to price control versus simplicity.
Quick checks
- Estimate requests, input size, output size, and peak-to-average traffic.
- List latency, privacy, model customization, and reliability requirements.
- Price idle GPU capacity and engineer time before declaring self-hosting cheaper.
Rough math
- API monthly cost = input usage + output usage + platform fees.
- Self-hosted monthly cost = GPU hours + storage + networking + observability + engineering overhead.
- Effective inference cost = total monthly serving cost / successful requests.
Red flags
- The comparison uses average traffic but ignores peak capacity.
- Self-hosting math excludes on-call, upgrades, monitoring, and failed deployments.
- API math ignores long outputs, retries, tool calls, or multi-step workflows.
What to do next
- Use the AI inference cost model for the formulas.
- Use the AI inference cost checklist to capture request and serving fields.
- Use useful GPU-hour examples when GPUs enter the comparison.
Related resources
Use a worksheet before making the call
These supporting pages turn the decision into fields a buyer, engineer, or founder can actually compare.
A practical checklist for estimating AI inference cost across APIs, managed inference, self-hosted GPUs, batch jobs, realtime endpoints, and hybrid routing.
GPU pricingGPU Cloud Quote ChecklistChecklist / 7 sections / source-linkedA practical checklist and visual worksheet for comparing GPU cloud quotes beyond the advertised hourly rate.
Product comparison
Compare specific infrastructure options
Once the decision points toward a product category, Infrabase can help compare specific AI infrastructure products.
Related decisions
Keep narrowing the placement question
Follow the adjacent pages when the first answer exposes a deeper cost driver or operating constraint.
A useful AI cost comparison compares serving categories by monthly cost, cost per successful request, latency, utilization, and operations burden, not by provider ranking.
AI inference costAI Cost Optimization: Practical Levers Before Rebuilding InferenceOptimization guideAI cost optimization usually starts with usage shape: reduce avoidable output, retries, failed calls, over-large prompts, expensive routing, and low utilization before changing infrastructure.
AI inference costBatch vs Realtime Inference Cost: How to ChooseCost estimationBatch inference is often cheaper when latency is flexible because work can be queued for higher utilization; realtime inference costs more when warm capacity and strict latency are required.
AI inference cost
When the GPU question is really serving cost
Use these pages when the same GPU quote, idle-cost, or useful GPU-hour question is about production inference rather than one-off training.
Framework
Use the underlying decision model
These framework pages define the terms and formulas behind this specific decision.
AI inference cost should be compared as effective cost per successful request and monthly serving cost, not just token price or GPU hourly rate.
GPU pricingUseful GPU-Hour Frameworkuseful GPU-hourUseful GPU-hour cost is the better comparison unit when GPU providers differ in utilization, queueing, reliability, storage behavior, or operational model.
AI inference cost quiz
Get an AI compute cost read
Compare total monthly serving cost per successful request, not token price against GPU hourly rate.
Uses actual request volume, latency, GPU need, data movement, priority, and ops tolerance.FAQ
Is self-hosted inference always cheaper at scale?
Self-hosted inference is not always cheaper at scale. It can be cheaper only when utilization, traffic predictability, latency needs, model control, and engineering capacity support the operating burden. Include idle warm capacity, storage, networking, monitoring, on-call, upgrades, and failed deployments before comparing it with API cost.
What is the biggest API versus self-hosting mistake?
The biggest API versus self-hosting mistake is comparing token price with GPU hourly rate. That skips the real denominator: total monthly serving cost per successful request. API math should include retries, long outputs, and tool calls; self-hosting math should include idle capacity and engineering overhead.
Should prototypes self-host inference?
Prototypes usually should not self-host inference unless privacy, control, or model constraints require it. API inference avoids carrying fixed GPU capacity while traffic, latency, output size, and product fit are still changing. Self-hosting can be revisited when usage is predictable and operations ownership is clear.
Sources
AI inference cost quiz
Get an AI compute cost read
Compare total monthly serving cost per successful request, not token price against GPU hourly rate.
Uses actual request volume, latency, GPU need, data movement, priority, and ops tolerance.